1.按照批次大小分类
可以分为随机梯度下降、批量梯度下降,二者的原理和性能有很多相关资料,不再赘述。其中,批量梯度下降方法性能更好,使用更为普遍,wuliang系统使用的就是批量梯度下降方法,目前在LR中batch size设置为1000,以后可以更改一下,对比一下实验效果。
2.按照优化方法进行分类
参照《深度学习》一书,目前主流的优化方法有分为基本优化算法、自适应学习率算法、二阶近似方法。wuliang系统原本支持传统的sgd,我此次共实现了六个算法,包括两个基本算法(Momentum、Nesterov)和四个自适应学习率算法(AdaGrad、RMSProp、Adam、AMSGrad)。
其中Adam在深度学习当中应用十分广泛,AMSGrad是ICLR 2018论文刚刚提出的新算法,受到了广泛的关注。目前集群资源比较紧张,方便起见我此次主要对比Sgd、Adam、AMSGrad的效果。
3.实现思想
基于wuliang原本的lr和sgd设计思想,我既可以将优化方法放到worker端(KVWorkerTableMultiThread.h),又可以放到server 端(AdamServerTable.h),但是最后决定放到server端,主要基于以下几种考虑:
- server端目前只负责存储,没有大量的计算任务,CPU很空闲,优化方法放到server端实现可以利用这些空闲的CPU,减少worekr端额外的计算负载。
- 如果放到worker端,需要本地另申请空间存放一阶矩和二阶矩,并且需要在所有epoch当中都需要一直存储,直观上感觉会占有比较大的空间。
- Adam中有一个变量是时间步t,t随着计算梯度的次数而增加,单机实现的话属于全局参数,现在在分布式环境中,如果放到worker端就会变成局部参数(以worker为单位),放到server端就还是全局参数。
- 放到worker端,一阶矩和二阶矩需要用unordered_map存储;放到server端可以使用vector存储,索引时间有优势。
前五种算法实现参照《深度学习》一书,AMSGrad参照其论文和网上资料实现。
4.实验
数据:来源于Tencent业务侧数据,现在选取的是前一天的数据(2018.4.1)做train(53022663行),后一天的数据做test(53022665行),特征维度是百亿,数据稀疏度是(0.001 即1000个空间中只有一个有值)。
场景:LR算法用于点击率预估
超参数:
每个worker只开了两个task(wahmingchen说开两个线程基本就CPU跑满了)
minibatch=1000
epoch=50
reg=3
reg_value=0.1
consistency=bsp
1. sgd: learningrate=0.1(wahmingchen说这个最好)
2. Adam(实验效果最好,也和书上的建议值完全一致):learningrate=0.001 rho1=0.9 rho2=0.999
3. Amsgrad:learningrate=0.001(虽然论文建议学习率对比Adam要小一点,但是公平起见,还是和Adam一样了) rho1=0.9 rho2=0.999
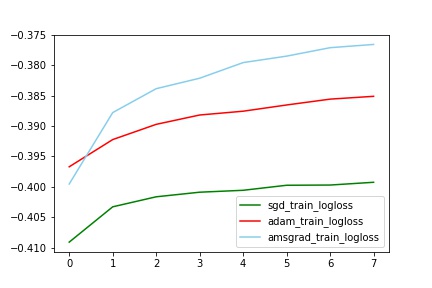
对比train_logloss
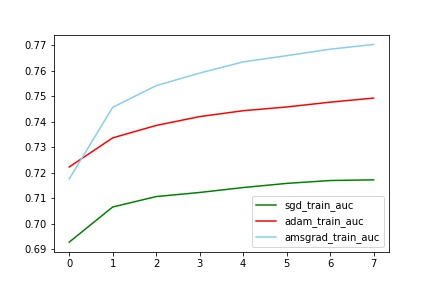
对比train_auc
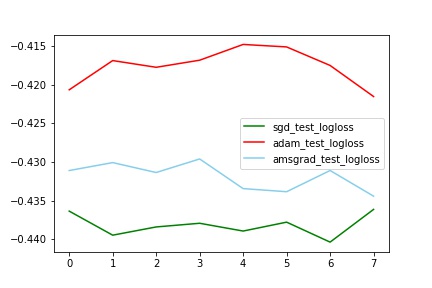
对比test_logloss
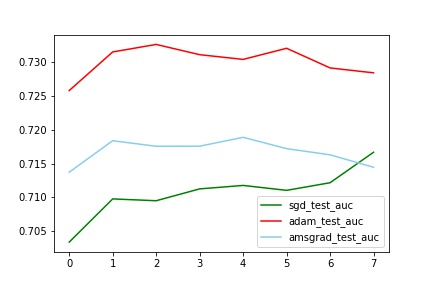
对比test_auc
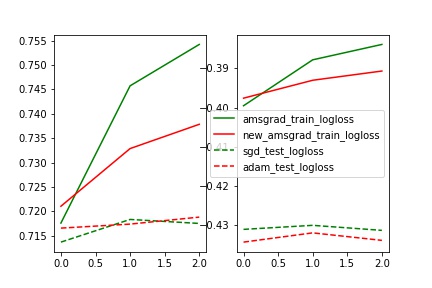
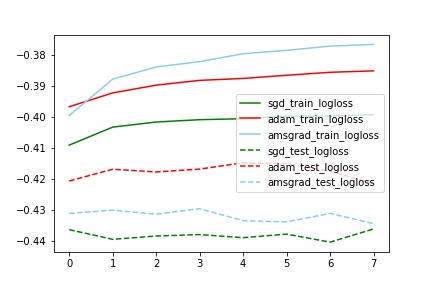
对比train_test_logloss
对比train_test_auc
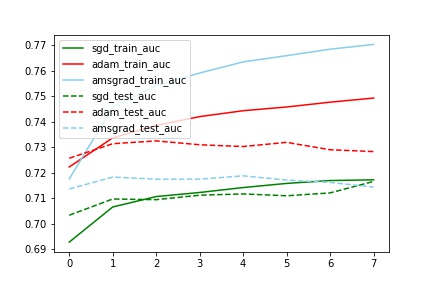
分析:
auc和logloss变化基本一致
train中AMSGrad拟合最好(与其他两个有明显差别,甚至auc到达了0.77,这个想想为什么?),但是test中Adam效果最好(比sgd的auc提高了2%)
train_test_auc中,sgd的train和test基本一致,但是Adam和Amsgrad中train和test相差比较大。(也不知道为什么)
其他
另外:
- AMSGrad论文中没有采用偏差修正,因此上述实验我也没有偏差修正,实验了一下有偏差修正的AMSGrad,无偏差修正效果更好一点,但是只跑了三轮迭代,可能没有什么说服力。