- volatile的可见性是指每当有其他线程对变量发生改动后,我这个线程在读取的时候都是最新值。
2015《Scalable Distributed DNN Training Using Commodity GPU Cloud Computing》
作者:Strom
Abstract
1.对象:DNN GPU Gloud
2.方法:独立控制每一个权重的更新频率。
3.效果:总的通信量降低了三个数量级,收敛率(convergence rate)和准确率(accuracy)没有降低。
1.Introduction
3.并行训练也可以转化为模型并行问题。对于稀疏结构化连接层(CNN),可以有效分配每层的计算;对于全连接层,每一层可以由不同节点进行处理。由于紧密连接的网络,模型并行受到DNN层数的限制,因此本篇工作只研究数据并行的问题。(数据并行可以和模型并行进行合并)
2.Method
2.1Data-parallel distributed SGD
减少通信量的方法:1.减少同步的频率 2.压缩梯度
2.2Two observations
1.很多SGD加速方法可以看作是延迟更新的变体:minibatch、Momentum、Nesterov、double buffering、asynchronous SGD
2.对于全连接DNN来说,子梯度十分稀疏,因此对于接近于0的梯度,可以延缓更新。
2.3Compaction and dead reckoning
2.string compaction(与GPU有关的技术,好像和本文关系不大?)
3.dead reckoning:所有计算节点的更新逻辑相同(没什么,不值得再看)
2.4Gradient residual
1.由于不同权重的大小不同,因此不能简单丢弃低于阈值的梯度。
2.所有权重最后都被更新。
2.5Quantization and compression
1.索引和梯度都被pack,最终一个键值对以32 bit的int表示。
2.量化误差(error feedback)要被累加到residual
3.进一步压缩:entropy coding——不记录值的大小,记录值之间的差值。(3倍压缩率,因为需要额外的时间成本,因此本文没有使用)
2.6Pseudo code
一个minibatch的过程:
1.从其他节点接收、解压梯度,累加到本地模型参数上
2.加载一个minibatch的训练数据
3.BP计算子梯度Gs
4.累加梯度:Gr=Gr+Gs
5.重置消息Map:M
6.对于每个元素gi:
7.若gi>+阈值(t):
将{i,+t}加入到M中
gi=gi-t
否则若gi<-阈值(-t):
将{i,-t}加入到M中
gi=gi+t
8.压缩M,然后发送到其他节点
3.Experiments
3.1环境:AWS
3.2用单机结果作为baseline
3.3
1.使用了预训练;
2.另外,为了避免低性能,第一个epoch,使用了更小的minibatch size和计算节点。(为什么可以改善)
实验的其他细节省略了
4.Discuss
该方法不能无限制扩展节点:
1.随着节点数目增大,batchsize过大,容易不收敛。(1.节点数目和batch size是什么关系? 2.batchsize过大,为什么不收敛?)
2.随着节点数目增多,通信可能再次成为瓶颈。
5.Conclusion
1.该方法有效扩展了规模:80GPU
2.模型越大,方法的优越性越显著
2014《1-Bit SGD and its Application to Data_Parallel Distributed Training of Speech DNNs》
作者:Frank Seide 、 Dong Yu
摘要:
1.主要思想:只要量化损失(quantization error)被带到下一个minibatch,就可以实现1-bit的无损压缩。
2.方法:和Adagrad、自动minibatch大小调节、双缓冲、模型并行结合。
3.压缩率:没有提及。只是说了提速多少。
Introduction
4.R-prop方法好像可以直接丢弃上一个minibatch的信息(这个不确定,后续调研一下R-prop方法)
5.介绍其他加速训练的方法:低阶近似(low-rank approximations)、二阶方法(Hessian Free)、模型平均、ADMM。(这些方法都不了解,后续可以看一下,但是都好像和梯度压缩无关,所以暂时略过)。
6.第六段和DNN的关系比较大,后续问问wamingchen。
和Hogwild/ASGD不同,该方法是确定性不改变收敛性能的方法。(比较怀疑这个说辞)
2
2.1数据并行分布式SGD
讨论了通信时间和计算时间的关系,并由两者确定最佳的节点数量K。(其中的公式没有看懂,后续一定要再看一下!)
2.2利用双缓存对minibatch进行切分
将minibatch分成前一半和后一半。push前一半梯度的同时,计算后一半的梯度。(文献19、8应该是介绍了这个技术)
3. 1-bitSGD with Error Feedback
1.量化误差不应该被抛弃,否则会导致不收敛。
2.通过公式可以看出来,就是计算出量化误差,然后累加到下一个minibatch当中。(下标表示什么没有看明白)
3.将0作为量化阈值(如何量化得????)
3.1集成梯度
每一个minibatch需要经历两次quantization。(这里也没想明白,回头再看看!)
4系统描述
1.增加minibatch大小可以增加数据并行度,但是太大容易导致模型不收敛(这个还不理解为什么?)。因此这个系统前期先在小数据上确定可以最大的minibatch size。
2.训练过程中使用交叉验证动态调整学习率的衰减系数。
3.使用了Adagrad,它可以收敛得更快,并且允许更大的minibatch size。
4.可以在三个地方使用Adagrad:
4.1 量化之前
4.2 量化之后:先集成子梯度,然后进行Adagrad
4.3 进行动量平滑之后
目前看,4.2效果最好。(文章也不知道为什么这样效果最好)
5实验
5.2 1-bit量化的影响
1.前期阶段没有使用梯度量化和并行化(冷启动:冷启动和热启动的区别是啥?)
2.error feedback很关键,一定要加上。
6结论
2017《DEEP GRADUIENT COMPRESSION》
作者:Song Han
摘要:
1.DGC:DEEP GRADUIENT COMPRESSION
2.前提:99.9%的梯度都是没有用的
3.方法:动量修正、本地梯度缩放、动量因子遮蔽、热启动。
4.压缩倍数[270,600]->压缩率[0.003703704,0.001666667]。注意,是无损压缩。
5.对象:CNN、RNN。
1.介绍
1.动量修正、本地梯度缩放:保证了无损压缩。
2.动量因子遮蔽、热启动:缓解了参数陈旧的问题。
2.相关工作
1.For instance, asynchronous SGD accelerates the training by removing gradient synchronization and updating parameters immediately once a node has completed back-propagation(这个后续了解一下)
2.梯度量化:1—bit SGD、QSGD、TernGrad(3-level)、DoReFa-Net(1-bit weights with 2-bit gradients)
3.梯度稀疏化:主要思想是利用thresold进行裁剪。具体方法参加原文。
4.DGC:600倍压缩,无损,不需要额外的layer normalization,无需更改模型结构。
3.DGC
3.1梯度稀疏化
1.仅传输重要的梯度,简单认为绝对值大的梯度就重要(这个真的对吗?)。
2.要累积没有发送的梯度,在以后进行发送。保证到最后所有的梯度都被发送了。
3.使用encode方法进行发送(没有看懂encode方法:The encode() function packs the 32-bit nonzero gradient values and 16-bit run lengths of zeros.)
4.本质上就是将minibatch的大小由Nb增长为NbT。(具体见公式)
3.2增加本地累积的准确率
一旦单次传送梯度的稀疏度很高,就破坏了收敛。动量修正、本地梯度缩放可以减缓这个问题。
动量修正
当使用动量算法作为优化器时,直接传送裁剪后的梯度就忽略了discounting factor,破坏了收敛。
解决方法:由传输梯度改为传输动量:本地计算动量,裁剪动量(相应也是累积动量),传送动量。
(感觉逻辑上有问题,本地的动量和全局动量应该不是一回事儿吧)
本地梯度缩放
前人方法:梯度的L2范数总和超过阈值就进行缩放,步骤:收集各个节点梯度,求和,缩放,累加。
DGC:利用乘上sqrt(N)进行缩放;步骤:先计算本地梯度G(t),然后进行缩放,然后加上G(t-1)。(这里有一个疑问:如果先加和再缩放呢?)
3.3避免参数陈旧问题
当模型稀疏度达到99.9%时,T=[600,1000],因此参数陈旧问题很严重。
动量因子遮蔽
步骤见公式
在公式7中,动量和累积量使用相同的Mask,没有解释原因,但从上文看,好像这样就足够好了。
注意这里面的thresold应该是和“3.1梯度稀疏化”中的thresold不同。
(疑问:其实就是去除了绝对值比较大的累积量,但是绝对值大就一定是陈旧的吗?为什么不用遍历次数进行衡量?)
热启动训练
结论:训练早期不应该进行梯度稀疏化。原因:早期的梯度有多样性和攻击性,如果不让发送就会限制变化范围,从而减缓收敛;累积早期梯度可能会误导收敛方向。
采用的方法:对于神经网络,训练早期采用攻击性小的学习速率,以减缓网络的变化速度;早期减缓梯度的稀疏度;渐变过程:随着epoch的增加, 不是线性增加学习速率,而是指数增常梯度稀疏度,文章认为这样可以帮助训练更容易适应较大的梯度稀疏度(为什么?)。
4实验
5系统分析和性能
在梯度稀疏化时,确定thresold很耗时。因此采用采样方法确定阈值。
利用 Wen et al. (2017) 提出模型进行测试。
调整集群数量和网卡配置进行对比。
6结论
未来将要分层设置thresold,用来加速梯度稀疏化的速度。
2017《Sparse Communication for Distributed Gradient Descent》
作者:Aji
Abstract
1.压缩率:99%
2.结合:和梯度量化结合
3.对象:MNIST(大多数配置都表现良好)、神经网络机器翻译任务(不同配置各有好坏)
4.MNIST:49%的提速;NMT:22%的提速。注意:都没有损失准确率。
1.Introduction
2.Related Work
介绍了一些文章,我都下载了,看一下!
3.Distributed SGD
4.Sparse Gradient Exchange
2.直接将小于阈值的梯度设置为0会破坏收敛性,因此需要将它们累加到下一个minibatch。
4.取样0.1%选取thresold
5.分别是用了local thresold和global thresold(结合了layer normalization)
5.Experiment
5.1确定压缩率(这个可以动态调整吗?)
2.99.9%的压缩率导致很不好的压缩性能,99%的几乎不影响性能,
5.2局部threshold VS 全局thresold
1.只实现了thresold_push,没有实现thresold_pull(Based on the results and due to the complicated interaction with sharding, we did not implement locally thresholded pulling, so only locally thresholded pushing is shown.)
2.layer normalization只对NMT有效,对MNIST几乎没什么影响。
5.3收敛速度
通过缩小minibatch大小,强行增加通信时间,然后说自己的梯度压缩增快了收敛速度,这个实验稍显牵强。
5.4 1-bit quantization
1.列举了一些梯度量化的方法
2.三种层次的量化方法:min thresold、column、_wise average thresold、global average。(实验图看 应该是global average thresold效果最好 感觉这个依赖具体场景)
3.1-bit可能影响收敛速度,2-bit一般是足够的,因为它可以将小梯度和大梯度区分开了。
Conclusion
2017《AdaComp:Adaptive Residual Gradient Compression for Data-Parallel Distributed Training》
作者:Chia-Yu Chen
写在前面:
这片论文的引用量目前只有被Hansong引用过,感觉算不上是经典论文,但提出了自适应的思路,因此看了一下。
Abstract
1.压缩率:对于全连接层:200倍压缩;对于CNN,40倍压缩。
2.优势:适用于各种领域(vision、speech、language),各种数据集,各种优化器。
3.方法:稀疏化和量化
4.总结:AdaComp是基于本地的梯度累积进行选择,并且可以本地情况自动调节压缩率。
1.Introduction
3.之前的工作都是对全连接层进行压缩,本文提出的工作还适用于卷积层等多种复合结构,并且准确率和收敛率的损失可以忽略不计。
2.Residual gradient compression
Background
Strom 2015:只有梯度值超过指定阈值,才会被量化为1bit进行传输。
之前的工作都没有讨论如何选择阈值。
Dryden:不是选择固定阈值,而是固定每次的传输百分比,但需要预先对所有梯度进行排序,这是一个代价比较高的计算任务。
所有的工作都基于一个准则:未被发送的梯度都累积了下来。
Observations
第一个发现:
对于裁剪来说,不应该只考虑梯度的大小,还应该考虑数据和数据对特征活跃度的影响。因为可能有的梯度虽然值很小,但它们可能连接的高活跃度的输入特征。
累积梯度对特征活跃度几乎没有什么影响。
第二个发现:
对于神经网络来说,网络结构、层的类型、minibatch的大小、其他参数都会影响压缩率,因此需要动态地、自动地调整压缩率。
最后,为了减小成本,本文避免了排序,并且基于本地数据进行压缩。
Adaptive Residual Gradient Compression(AdaComp) Technique
1.其实核心思路就是将所有参数进行了分桶(第一段记录了策略:根据网络结构进行分桶),先找到每一个bin中的累积量的最大值,然后一旦(累积量+factor*新的梯度)超过了这个最大值,就把(累积量+新的梯度)发送出去。
伪代码
residue:之前的累积量
dW:本轮计算的梯度
1 G=residue+dW
2 H=G+dW(其实就是H= residue+2*dW,2就是factor)
3 对于所有的桶:
计算该桶中的最大值,记为gmax
4 对于每一个桶:
对于桶中的每一个值:
若 Hi>gmax:
就将G进行量化、发送
residual记录了量化误差
否则:
residual记录了G,保存在本地。
3.实验
这个没来得及看,后续看一下。
4.讨论
这个没来得及看,后续看一下。
优化方法:梯度下降 总结
1.按照批次大小分类
可以分为随机梯度下降、批量梯度下降,二者的原理和性能有很多相关资料,不再赘述。其中,批量梯度下降方法性能更好,使用更为普遍,wuliang系统使用的就是批量梯度下降方法,目前在LR中batch size设置为1000,以后可以更改一下,对比一下实验效果。
2.按照优化方法进行分类
参照《深度学习》一书,目前主流的优化方法有分为基本优化算法、自适应学习率算法、二阶近似方法。wuliang系统原本支持传统的sgd,我此次共实现了六个算法,包括两个基本算法(Momentum、Nesterov)和四个自适应学习率算法(AdaGrad、RMSProp、Adam、AMSGrad)。
其中Adam在深度学习当中应用十分广泛,AMSGrad是ICLR 2018论文刚刚提出的新算法,受到了广泛的关注。目前集群资源比较紧张,方便起见我此次主要对比Sgd、Adam、AMSGrad的效果。
3.实现思想
基于wuliang原本的lr和sgd设计思想,我既可以将优化方法放到worker端(KVWorkerTableMultiThread.h),又可以放到server 端(AdamServerTable.h),但是最后决定放到server端,主要基于以下几种考虑:
- server端目前只负责存储,没有大量的计算任务,CPU很空闲,优化方法放到server端实现可以利用这些空闲的CPU,减少worekr端额外的计算负载。
- 如果放到worker端,需要本地另申请空间存放一阶矩和二阶矩,并且需要在所有epoch当中都需要一直存储,直观上感觉会占有比较大的空间。
- Adam中有一个变量是时间步t,t随着计算梯度的次数而增加,单机实现的话属于全局参数,现在在分布式环境中,如果放到worker端就会变成局部参数(以worker为单位),放到server端就还是全局参数。
- 放到worker端,一阶矩和二阶矩需要用unordered_map存储;放到server端可以使用vector存储,索引时间有优势。
前五种算法实现参照《深度学习》一书,AMSGrad参照其论文和网上资料实现。
4.实验
数据:来源于Tencent业务侧数据,现在选取的是前一天的数据(2018.4.1)做train(53022663行),后一天的数据做test(53022665行),特征维度是百亿,数据稀疏度是(0.001 即1000个空间中只有一个有值)。
场景:LR算法用于点击率预估
超参数:
每个worker只开了两个task(wahmingchen说开两个线程基本就CPU跑满了)
minibatch=1000
epoch=50
reg=3
reg_value=0.1
consistency=bsp
1. sgd: learningrate=0.1(wahmingchen说这个最好)
2. Adam(实验效果最好,也和书上的建议值完全一致):learningrate=0.001 rho1=0.9 rho2=0.999
3. Amsgrad:learningrate=0.001(虽然论文建议学习率对比Adam要小一点,但是公平起见,还是和Adam一样了) rho1=0.9 rho2=0.999
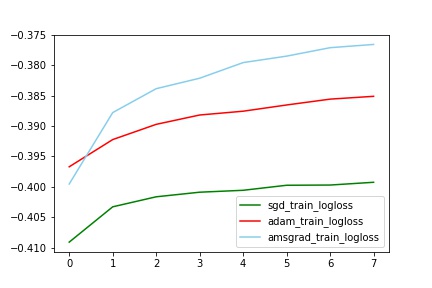
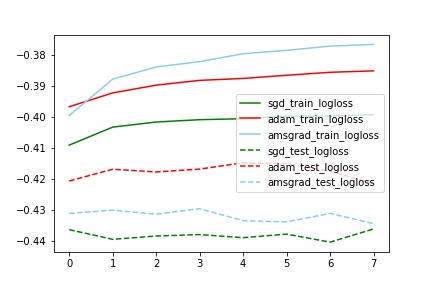
对比train_logloss
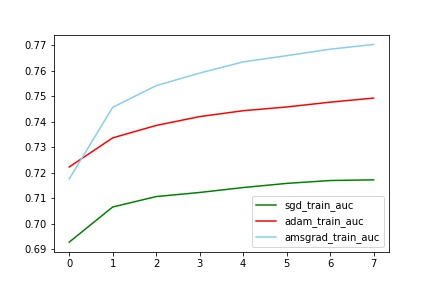
对比train_auc
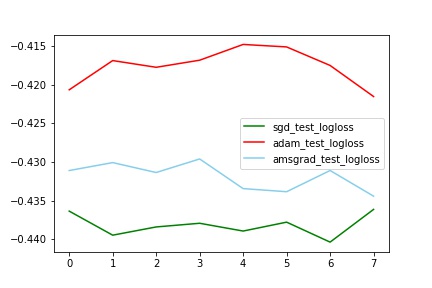
对比test_logloss
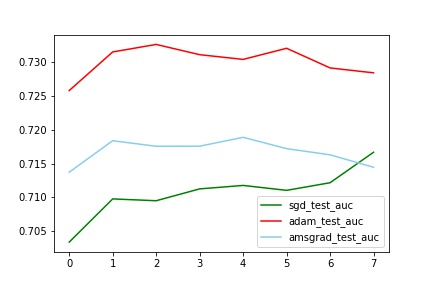
对比test_auc
对比train_test_logloss
对比train_test_auc
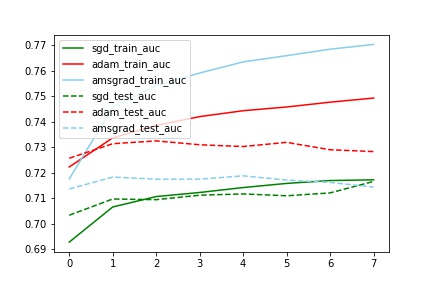
分析:
auc和logloss变化基本一致
train中AMSGrad拟合最好(与其他两个有明显差别,甚至auc到达了0.77,这个想想为什么?),但是test中Adam效果最好(比sgd的auc提高了2%)
train_test_auc中,sgd的train和test基本一致,但是Adam和Amsgrad中train和test相差比较大。(也不知道为什么)
其他
另外:
- AMSGrad论文中没有采用偏差修正,因此上述实验我也没有偏差修正,实验了一下有偏差修正的AMSGrad,无偏差修正效果更好一点,但是只跑了三轮迭代,可能没有什么说服力。
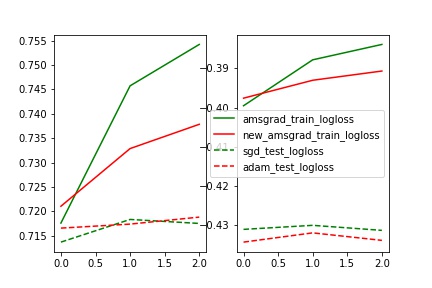
Tencent无量 多线程push&pull实现
实现的初衷
对于参数服务器来说,影响速度性能的主要有两方面的因素:
- 第一是worker的计算能力,所以可以利用Eigen库对worker上的计算过程进行优化、减少计算的时间;
其次就是网络通信,worker和server都需要对消息进行收发,并且经常要等到对方的消息才能进行后续操作。这方面我能想到的有两点可以优化的方向。
2.1 第一就是尽量减少网络带宽,以梯度g的push和pull为例进行说明。首先,我们可以牺牲梯度的精度用来减少网络带宽,之前g的精度是64位的double,如果可以用32位的float进行代替,就显著减少了网络通信量,这只是很初级的优化,百度的PaddlePaddle有了进阶的优化–梯度量化。另外,也可以进行User-defined Filters——支持用户自定义过滤器来过滤掉那些比较小的被push的entry。需要说明的是,这只是我知道的两种方法,由于此篇的重点不在此,就不详细展开了。
2.2 第二就是缩短对于通信消息的处理时间,对于无量系统来说,之前是单线程对消息进行处理,以server为例进行说明,PSServer拥有一个Customer对象负责消息的收发,通过std::bind对PSServer::process函数进行绑定,消息的处理流程都是在process里面进行的,对于Customer的实现机制我还不太了解,但是通过process的函数参数可以看到每次只能处理一条消息,具体流程是收到消息,对消息进行拆解,然后调用相关函数对消息的请求进行处理,最后发回反馈信息,对于server来说,每一时刻只能处理一条消息,这样即使此时还收到了其他消息,这些消息的处理也需要被阻塞,进而消息的发送者也需要等待,这就增加了网路通信的时间成本。
如何优化
通过2.2的瓶颈分析,我们发现server端“每次只能处理单条消息”大大增加了网络通信的延时,另外目前server主要的功能就是参数的存储,也就是说对Memory的利用比较充分,但是由于server没有什么复杂的计算,所以对CPU的利用率很低。自然,我们可以想到的是在server端通过多线程对消息进行处理,这样既可以减少网络的通信时间,也可以增加CPU的利用率,何乐而不为呢?
第一个想法:是对于push和pull各开一个线程池,分别有自己的消息队列。process收到消息后,先判断是push还是pull,meta.push\==1就塞进push的消息队列,meta.push\==0就塞进pull的消息队列(注意这里还需要仔细区分clock或者predict等操作,我还没仔细看,就不详细展开了,后续代码上也需要做进一步处理)。线程池中的线程直接从各自的消息队列中拿到消息,然后独自进行处理。这样,server端就可以实现同时对多个消息进行处理。进一步思考,我们发现push消息和push消息同时进行处理,pull消息和pull消息同时进行处理,push消息和pull消息同时进行处理。这三种并行机制有没有什么问题呢,对于pull来说,是从server读消息,所以同时pull没有问题;但是push是写参数,如果同时写到同一个参数,或者同时读写一个参数,由于对server_table没有加锁,就会出现逻辑问题(什么问题??)(也可能core掉)。另外,由于push和pull是独立进行处理,所以在pull一批参数的时候,worker可能获得不同迭代次数的参数,记得这样会导致收敛变慢或者不收敛的问题(这个具体记不清楚了,需要后面查一下资料),但好像单线程处理也会出现这样的问题啊?或者说这个问题是问题吗?
第二个想法:第一个想法的数据一致性问题比较严重,因此做一下改进。在多个server存在的情况下,我们是将一个大的模型表分布式存储在各个server中,每个server独自负责表的一部分——也就说按照server为单位对模型表进行划分,依此类推,我们更加细化——按照线程为单位对模型表进行划分。在“server独自负责表的一部分”基础上,一个server中的每个线程独自负责“一部分”的一部分。定性分析一下如此实现和之前的不同:
- 对于worker端来说,之前每次发送请求的时候是需要计算每个数据应发送到哪个server就行,即按照server为单位对数据进行拆分(partition)和打包发送(send),现在在WorkerImp中请求的数据key是按照线程为单位进行划分,即首先按照server为单位进行划分,然后再按照线程为单位进行划分,因此需要对partition函数进行重写,即增加了计算量和处理流程。
- WorkerImp原来针对每个server发送一次请求——数据包比较大,现在WorkerImp针对每个线程发送一次请求,即把原来的大数据包拆分成了小数据包,这样每次的数据包比较小,但是发送消息的频率显著增加了,倍数略等于server端开的线程数目。把大包拆解成小包,是能加快通信还是延缓通信,这个应该到生产环境中进行评测的。
- 考虑极限情况,频繁进行push和pull操作的话,消息队列的长度将会非常大。
实现细节
worker端:
- WorkerImp增加两个函数multi_pull和multi_push,和之前pull、push的不同在于分线程对key进行处理,分别发送消息。这里有一个小坑:在worker端msg.meta.threadindex要被赋值,这样server端才能根据threadindex将不同的消息分发给不同的线程,但是仅仅在这里设置是无效的,在van.cc里面,函数Van::PackMeta还需要进行pb.set_threadid(meta.threadindex)设置,对应Van::UnpackMeta还需要进行meta->threadindex = pb.threadid()设置,因此需要对meta.proto也增加threadindex字段。
- 目前只是在multi_pull和multi_push里面对msg.meta.threadindex进行了赋值,对于clock操作没有实现multi_clock功能,因此在server端都是threadindex=0的线程执行clock操作,之所以没有实现主要是考虑到clock操作本身就很复杂,并且调用的频率应该不是很频繁,因此直观上感觉指定threadindex=0的线程进行处理也没有什么问题。
- 新增文件kv_worker_table_multi_thread.h,和kv_worker_table.h对比,其实就是重新实现了partition函数,其中函数参数out的类型发生了改变,比原来的out内部多了一层vector,用来存储不同的线程应该接收到的消息。目前只实现了hash_partition,没有实现range_partition。
- 在lr_minibatch.cc里面需要在void StartServer()和void RunWorker()分别设置
'''GlobalContext::Get()->set_server_thread_num(server_thread_num);'''
因为是两个进程嘛,在全局参数的设置和读取其实都是独立的,需要各自去读配置文件。
ps端:
- 增加了solve_thread.h,它内部维护一个消息队列,可以进行push、pull、clock、predict操作。
- ps_server.cc改动比较大,首先构造函数里初始化线程池,注册receive函数,receive函数可以针对不同的请求调用相关的函数。process函数和之前的功能不同了,现在只是将消息insert到不同的线程的消息队列中。
- (之前有一个问题没有发现,就是clock比较特殊。在server端处理worker端的clock请求的时候,所有的其他线程都不可以再进行其他原子请求的处理了(push、pull),因为)——这个仔细想了一下,应该是不用加锁,后续再想想实验一下。
其他说明:
- 注意和实现之前的优化算法不同,对于lr_minibatch.cc等这些有main函数的文件来说,我们只需要更改worker注册的模型表(因为需要更改消息分发的机制),比如之前用的是KVWorkerTable,现在用的是KVWorkerTableMultiThread,对于server端来说没有任何变化(优化算法仅需要更改server端的注册模型表)。
性能评测
评测主要在传统sgd和adam上进行,这两个算法在server端的逻辑有不同。
先看server端单线程的情况:对于sgd来说,单纯看pull和push的耗时,是相同的,都是0.001秒;而对于Adam来说,push操作具有比较繁琐的计算过程,因此push的操作是0.01秒,pull的耗时不变——还是0.001秒。我打印了server端的消息队列长度,对于sgd来说,队列的长度一般是0、1、2,即基本没有阻塞,server端的push和pull操作的for循环很快,不是server和worker交互时的瓶颈;但对于adam来说,push操作很耗时,因此server端复杂的计算过程成为了交互时的瓶颈,消息队列的长度是180、190这么长。因此,adam一个minibatch时间都很长(3.5s左右),一个epoch耗时208min。sgd一个minibatch时间约为0.5s(0.3s——0.6s之间),一个epoch耗时34min。
现在在server端多线程push&&pull(线程池大小为40,因为server申请了40个CPU),对于adam来说,每个线程的消息队列长度基本就是0了,峰值的时候会到达18、19(极少情况会出现,但是没有想明白为什么会出现峰值情况)。每个线程的消息队列长度基本就是0,是因为每个push和pull操作相对于单线程时需要处理的量减少了很多(40倍),因此for循环的时间也急剧减少(pull的耗时为0,push的耗时一般也为0,有时会为0.001),这样就会和单线程sgd的情况一致了,server端的计算过程不会是两者交互的瓶颈,因此一个minibatch的时间基本和单线程sgd的时间差不多——0.6左右(0.6-0.8区间,除掉WorkerImp::process一些无用日志后,基本也就是0.5了),一个epoch耗时41min(除掉WorkerImp::process一些无用日志后,耗时缩减为33min),因此提升了6倍的速度。对于sgd来说,一个epoch耗时为32min,性能提升不多的主要原因是因为server端的for循环基本不是两者交互的瓶颈(从消息队列长度一般是0、1、2就可以看出来),有一点点提升是因为单线程有时消息队列还是被阻塞的(长度为1、2的时候)。
总结
之前其实比较纠结,相对于单线程来说,多线程处理到底好在哪里。现在知道了,通过多线程其实减少了server端for循环的耗时,只要for循环是server-worker交互的瓶颈,那么通过多线程可以将for循环的长度减少了,极大消除了瓶颈问题。